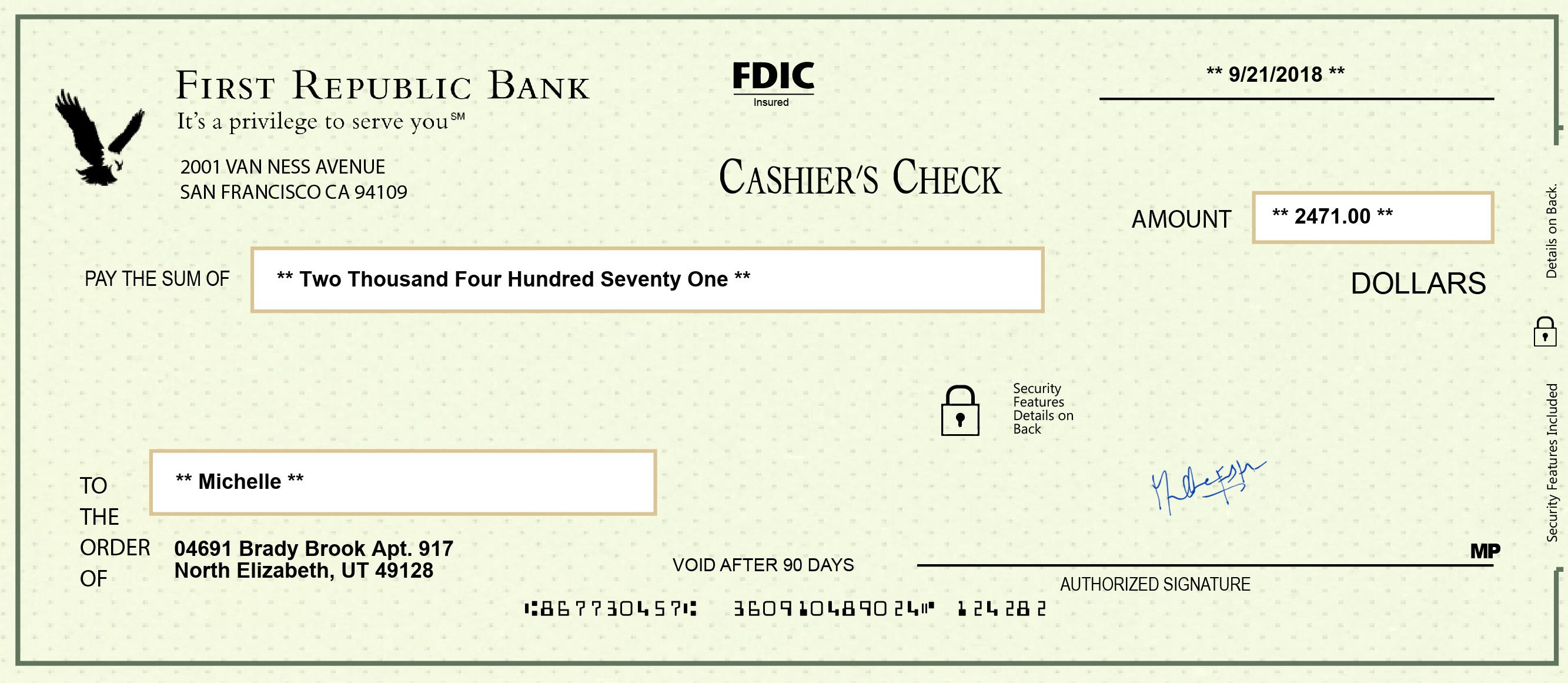
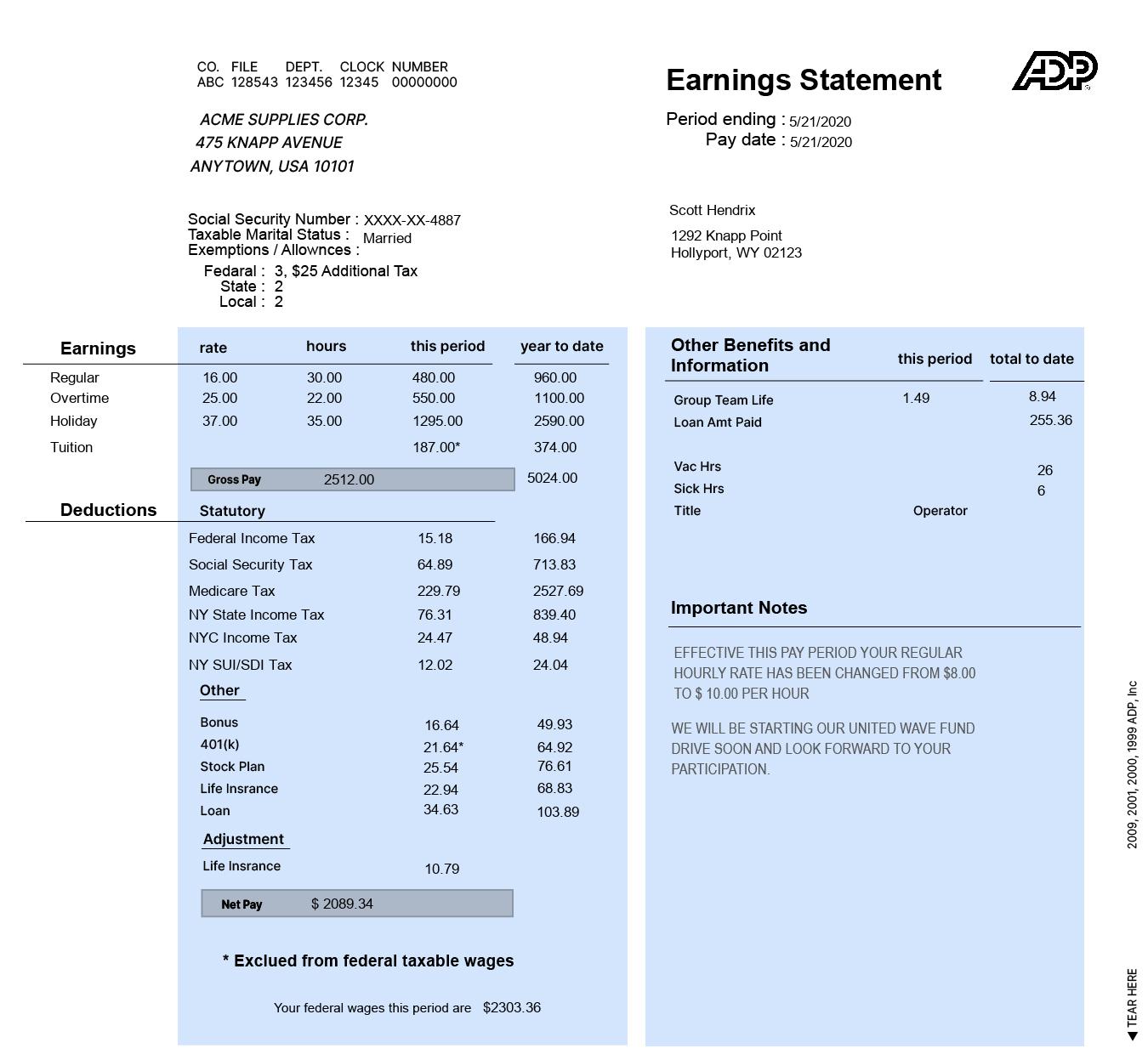
Real world Synthetic Dataset, that trains your algorithm to see beyond what you see!
Synthetic Dataset data that mimics production data might not be complete for obvious reasons.
Train your Computer Vision Algorithms such as Document Classifier Algorithms, with data that considers real world variables and are statistically significant, so that they can see beyond what you see in the real world.
Haidata’s proprietary synthetic document dataset generation methodology based on large scale generative modelling and Domain randomization provides data that is well balanced with consistent sampling, accommodating rare events, so that it can enable superior simulation and training of your models.
Haidata currently provides synthetic document datasets in the following domains and use cases.
- Internal Services - Visa application, Passport validation, License validation, Birth certificates, Driver's license
- Financial Services - Bank checks, Bank statements, Pay slips, Invoices, Tax forms, SSN ID Cards, Insurance claims and Mortgage/Loan forms and more
- Healthcare - Medical Id cards
We also design and develop new synthetic documents as per customer requirements.